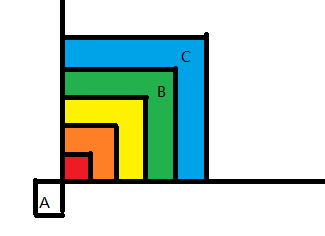
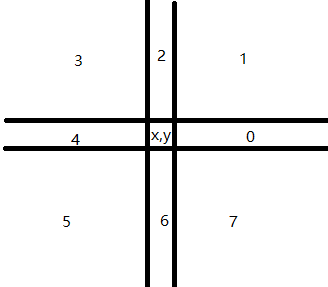1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
| #include<bits/stdc++.h>
using namespace std;
typedef unsigned long long ull;
typedef pair <int,int> Pii;
#define reg register
#define pb push_back
#define mp make_pair
#define rep(i,a,b) for(int i=a,i##end=b;i<=i##end;++i)
#define drep(i,a,b) for(int i=a,i##end=b;i>=i##end;--i)
template <class T> inline void cmin(T &a,const T &b){ ((a>b)&&(a=b)); }
template <class T> inline void cmax(T &a,const T &b){ ((a<b)&&(a=b)); }
char IO;
int rd(){
int s=0;
while(!isdigit(IO=getchar()));
do s=(s<<1)+(s<<3)+(IO^'0');
while(isdigit(IO=getchar()));
return s;
}
const int N=30011,INF=1e9+10,U=10000,D=6;
bool Mbe;
int n,m,k;
int X[N],Y[N],pre[N],vis[N];
vector <Pii> E[N];
typedef unsigned long long ull;
struct Bitset{
ull a[N/64+10];
int l;
void Add(int x){
while(1) {
ull t=a[x>>D];
a[x>>D]+=1ull<<(x&63);
if(t>a[x>>D]) x=((x>>D)+1)<<D;
else break;
}
cmax(l,((x>>D)<<D)+63-__builtin_clzll(a[x>>D]));
}
bool operator < (const Bitset &__) const {
if(__.l>10009) return 1;
if(l!=__.l) return l<__.l;
drep(i,(l>>D)+1,0) if(a[i]!=__.a[i]) return a[i]<__.a[i];
return 0;
}
} dis[N];
struct Queue{
int s[N<<2],bit;
void Up(int p) { s[p]=dis[s[p<<1]]<dis[s[p<<1|1]]?s[p<<1]:s[p<<1|1]; }
void Build(){
for(bit=1;bit<=n+1;bit<<=1);
s[bit+1]=1;
for(int p=bit+1;p;p>>=1) s[p]=1;
}
void push(int p) { for(s[p+bit]=p,p+=bit;p>>=1;) Up(p); }
int top(){
int res=s[1],p=s[1];
for(s[p+=bit]=0;p>>=1;) Up(p);
return res;
}
} que;
int Dis(int x,int y) { return max(abs(X[x]-X[y]),abs(Y[x]-Y[y])); }
int Ans[N],Ac;
int Min[N][8];
int Dir(int u,int v){
int x=X[v]-X[u],y=Y[v]-Y[u];
if(y==0) return x>0?0:4;
if(y>0) return x==0?2:(x>0?1:3);
return x==0?6:(x>0?7:5);
}
typedef vector <int> V;
V A[N],B[N];
int rtx[N],rty[N],ls[N],rs[N];
int Build(const V &vec,int l,int r){
if(l==r) return vec[l];
int mid=(l+r)>>1,u=++n;
ls[u]=Build(vec,l,mid),rs[u]=Build(vec,mid+1,r);
E[u].pb(mp(ls[u],-1)),E[u].pb(mp(rs[u],-1));
return u;
}
V Res;
void Que(const V &vec,int p,int l,int r,int ql,int qr){
if(!p) return;
if(ql<=vec[l] && vec[r]<=qr) return Res.pb(p);
int mid=(l+r)>>1;
if(ql<=vec[mid]) Que(vec,ls[p],l,mid,ql,qr);
if(qr>=vec[mid+1]) Que(vec,rs[p],mid+1,r,ql,qr);
}
void AddX(int u,int x,int l,int r){
int d=abs(x-X[u]);
if(rtx[x]) Que(A[x],rtx[x],0,A[x].size()-1,l,r);
for(int v:Res) {
E[u].pb(mp(v,d));
}
Res.clear();
}
void AddY(int u,int y,int l,int r){
int d=abs(y-Y[u]);
if(rty[y]) Que(B[y],rty[y],0,B[y].size()-1,l,r);
for(int v:Res) {
E[u].pb(mp(v,d));
}
Res.clear();
}
void Init(){
rep(i,1,k) A[X[i]].pb(i),B[Y[i]].pb(i);
rep(i,1,U) {
if(A[i].size()) {
sort(A[i].begin(),A[i].end(),[&](int x,int y){ return Y[x]<Y[y]; });
rtx[i]=Build(A[i],0,A[i].size()-1);
for(int &j:A[i]) j=Y[j];
}
if(B[i].size()) {
sort(B[i].begin(),B[i].end(),[&](int x,int y){ return X[x]<X[y]; });
rty[i]=Build(B[i],0,B[i].size()-1);
for(int &j:B[i]) j=X[j];
}
}
rep(i,1,k) rep(j,0,7) Min[i][j]=INF;
rep(i,1,k) rep(j,i+1,k){
int d=Dir(i,j),dis=Dis(i,j);
cmin(Min[i][d],dis);
cmin(Min[j][(d+4)&7],dis);
}
rep(i,1,k) {
if(Min[i][0]!=INF) AddX(i,X[i]+Min[i][0],Y[i],Y[i]);
if(Min[i][1]!=INF) {
AddX(i,X[i]+Min[i][1],Y[i]+1,Y[i]+Min[i][1]);
AddY(i,Y[i]+Min[i][1],X[i]+1,X[i]+Min[i][1]);
}
if(Min[i][2]!=INF) AddY(i,Y[i]+Min[i][2],X[i],X[i]);
if(Min[i][3]!=INF) {
AddX(i,X[i]-Min[i][3],Y[i]+1,Y[i]+Min[i][3]);
AddY(i,Y[i]+Min[i][3],X[i]-Min[i][3],X[i]-1);
}
if(Min[i][4]!=INF) AddX(i,X[i]-Min[i][4],Y[i],Y[i]);
if(Min[i][5]!=INF) {
AddX(i,X[i]-Min[i][5],Y[i]-Min[i][5],Y[i]-1);
AddY(i,Y[i]-Min[i][5],X[i]-Min[i][5],X[i]-1);
}
if(Min[i][6]!=INF) AddY(i,Y[i]-Min[i][6],X[i],X[i]);
if(Min[i][7]!=INF) {
AddX(i,X[i]+Min[i][7],Y[i]-Min[i][7],Y[i]-1);
AddY(i,Y[i]-Min[i][7],X[i]+1,X[i]+Min[i][7]);
}
}
}
bool Med;
int main(){
fprintf(stderr,"%.2lf\n",(&Med-&Mbe)/1024.0/1024.0);
n=rd(),m=rd(),k=rd(),n=k;
rep(i,1,k) X[i]=rd(),Y[i]=rd();
Init();
que.Build();
dis[0].Add(10111);
rep(i,2,n) dis[i].Add(10110);
while(que.s[1]) {
int u=que.top();
vis[u]=1;
for(auto t:E[u]) {
int v=t.first;
Bitset w=dis[u]; if(~t.second) w.Add(t.second);
if(w<dis[v]) dis[v]=w,que.push(v),pre[v]=u;
}
}
for(int u=k;u;u=pre[u]) if(u<=k) Ans[++Ac]=u;
printf("%d\n",Ac);
drep(i,Ac,1) printf("%d ",Ans[i]);
}
|